Loop engineering : ce que les boucles de Boris Cherny changent pour votre agence
Le concept de loop engineering éclaire comment les agents IA codent en boucle. Voici ce que cela signifie concrètement pour votre organisation.
35 articles publiés
Le concept de loop engineering éclaire comment les agents IA codent en boucle. Voici ce que cela signifie concrètement pour votre organisation.
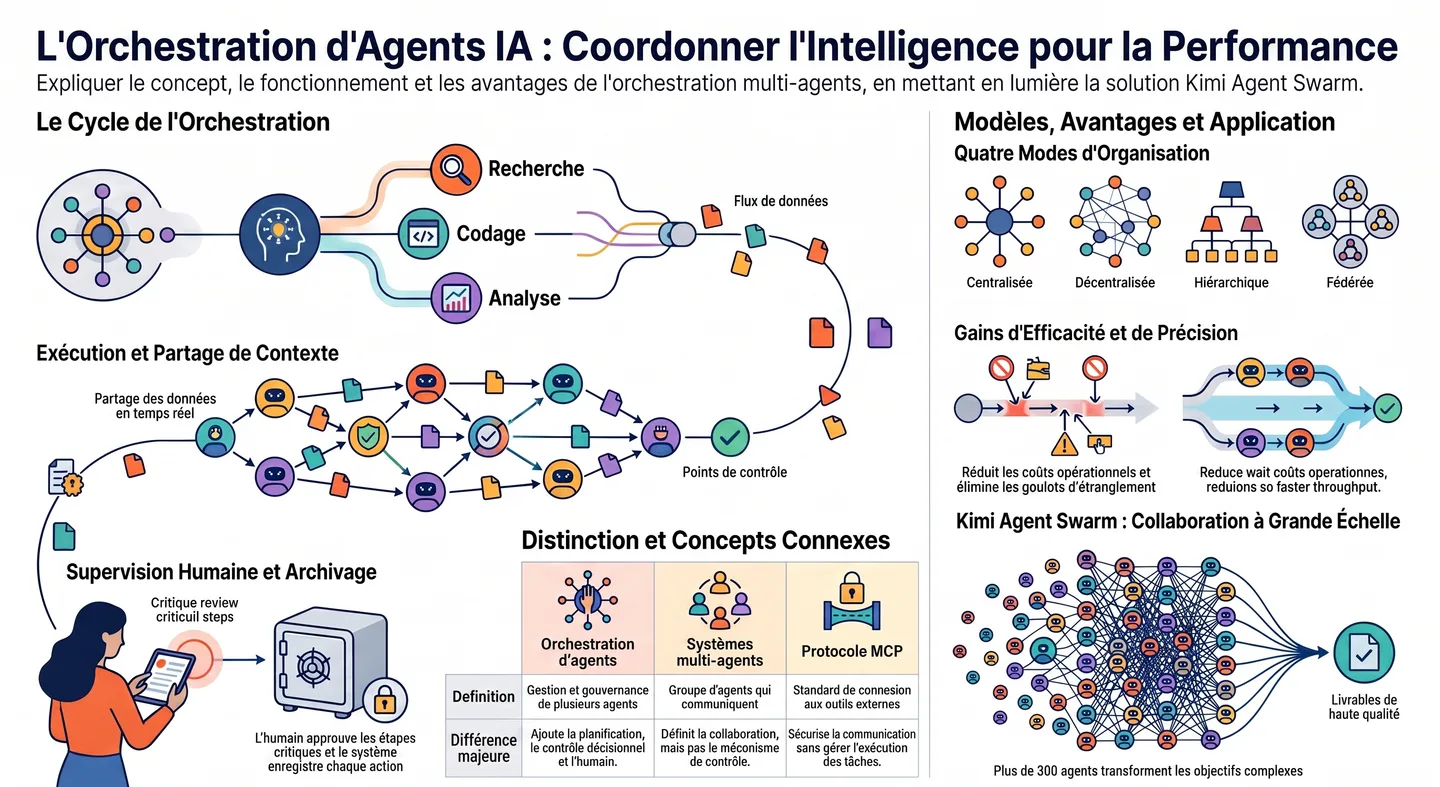
L'orchestration multi-agents promet des gains spectaculaires. Voici ce qui est solide, ce qui reste flou, et ce que ça change pour les PME.
Anthropic dévoile comment les grandes équipes configurent Claude Code. Voici ce qu'une PME ou une agence devrait en retenir.
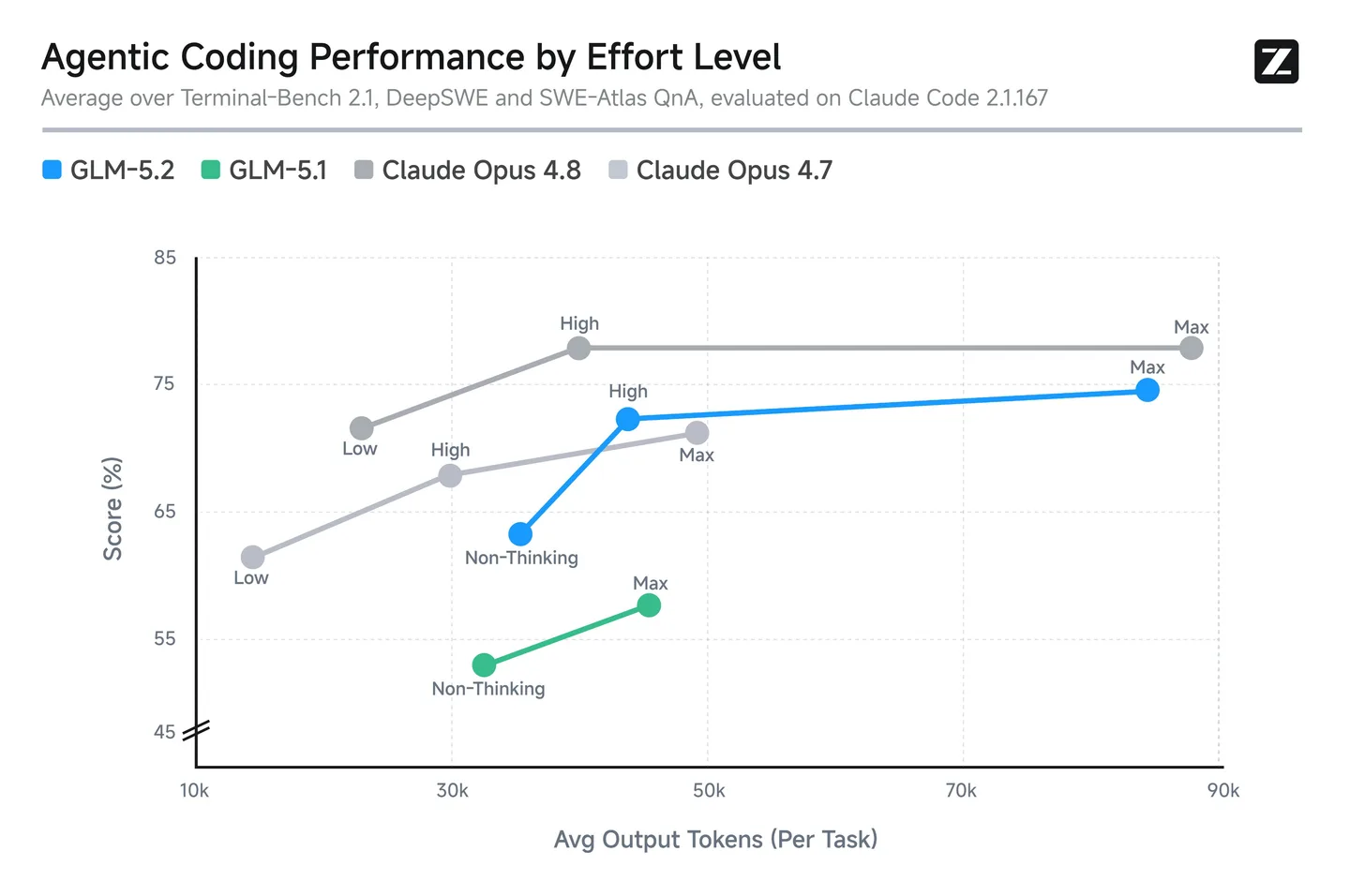
Z.ai lance GLM-5.2, un modèle open-source à contexte massif pensé pour les tâches longues. Ce que ça change pour votre stratégie d'outils IA.
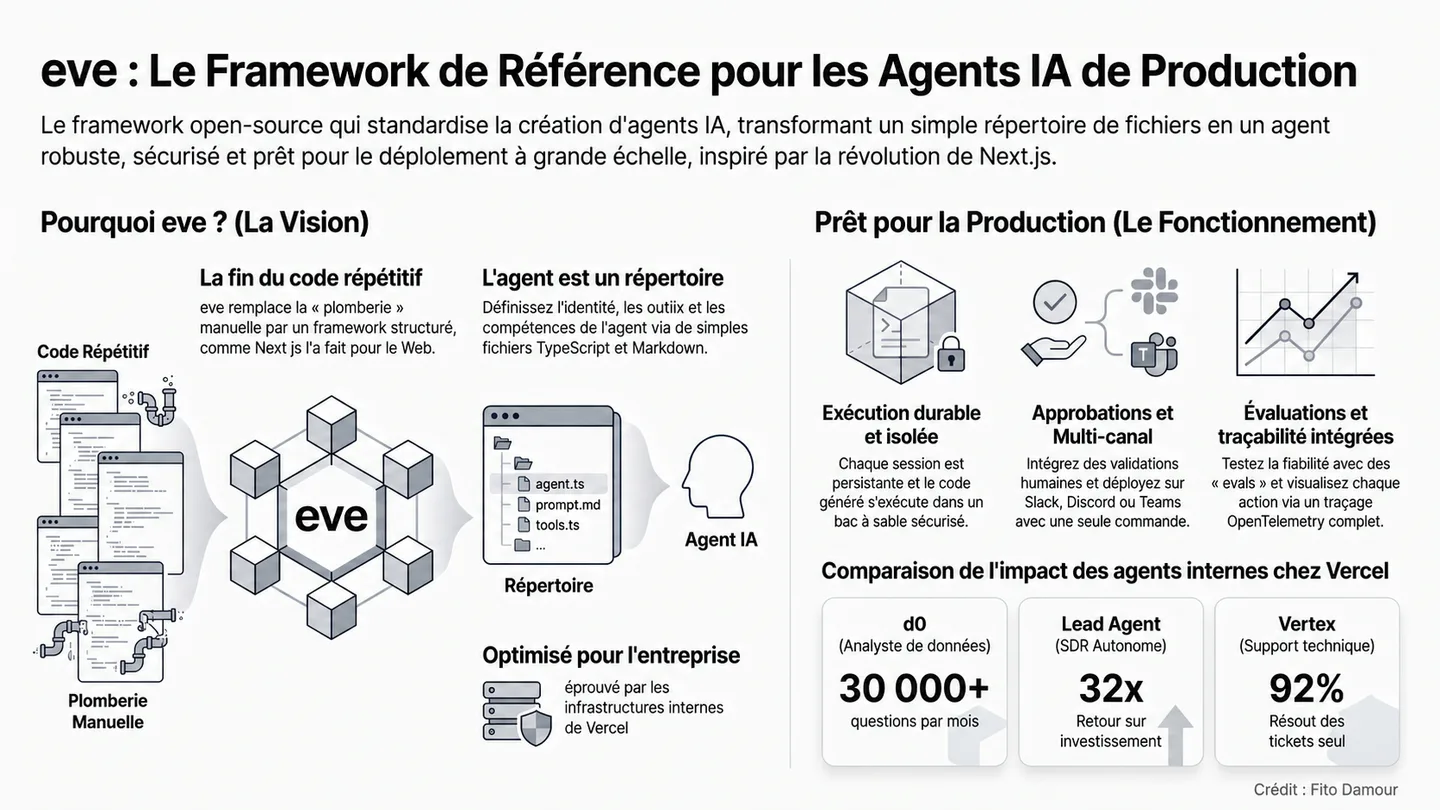
Vercel publie Eve, un framework open-source pour construire des agents IA fiables. Ce qu'il standardise, et ce qu'il ne règle pas pour votre organisation.
OpenAI offre ChatGPT Pro et Codex aux mainteneurs open source. Une vraie aide, et un signal sur la fragilité du logiciel libre.
Les 8 architectures RAG, de la plus simple à la plus complexe. Ce qu'elles font vraiment et laquelle choisir selon votre projet.
Découvrez AWS FinOps Agent (preview) : enquêtes d'anomalies, réponses FinOps en self-service et rapports automatiques, directement pour vos équipes.
Anthropic lance Claude Fable 5, premier modèle Mythos accessible au public. Lecture des impacts pour les organisations et les développeurs.
Apple pousse l'exécution d'agents IA directement sur Mac avec MLX. Confidentialité, latence, hors-ligne : ce que cette approche change pour les pros.
OpenSpec impose une couche de spécifications entre vous et votre assistant IA. Voici pourquoi cette approche change la donne pour les équipes techniques.
Comment combiner le développement piloté par les tests (TDD) avec Claude Code pour produire un code fiable, testé et maintenable.
Découvrez comment les dynamic workflows de Claude Code orchestrent des sous-agents en parallèle, avec validation croisée et relance.
Le Canada lance sa nouvelle stratégie nationale en IA. Au-delà des annonces, voici ce que cela change concrètement pour les PME et les organisations.
10 notions clés (tokens, embeddings, RAG, agents…) pour piloter un projet IA et éviter les pièges classiques des LLM.
Gemma 4 Unified 12B apporte vision + audio sans encodeur, jusqu'à 256K de contexte, et ouvre de vrais usages IA sur appareils.
Comprendre le rôle de FDE en IA, ses avantages et limites, et pourquoi la demande d'AI Engineers va largement dominer les prochaines années.
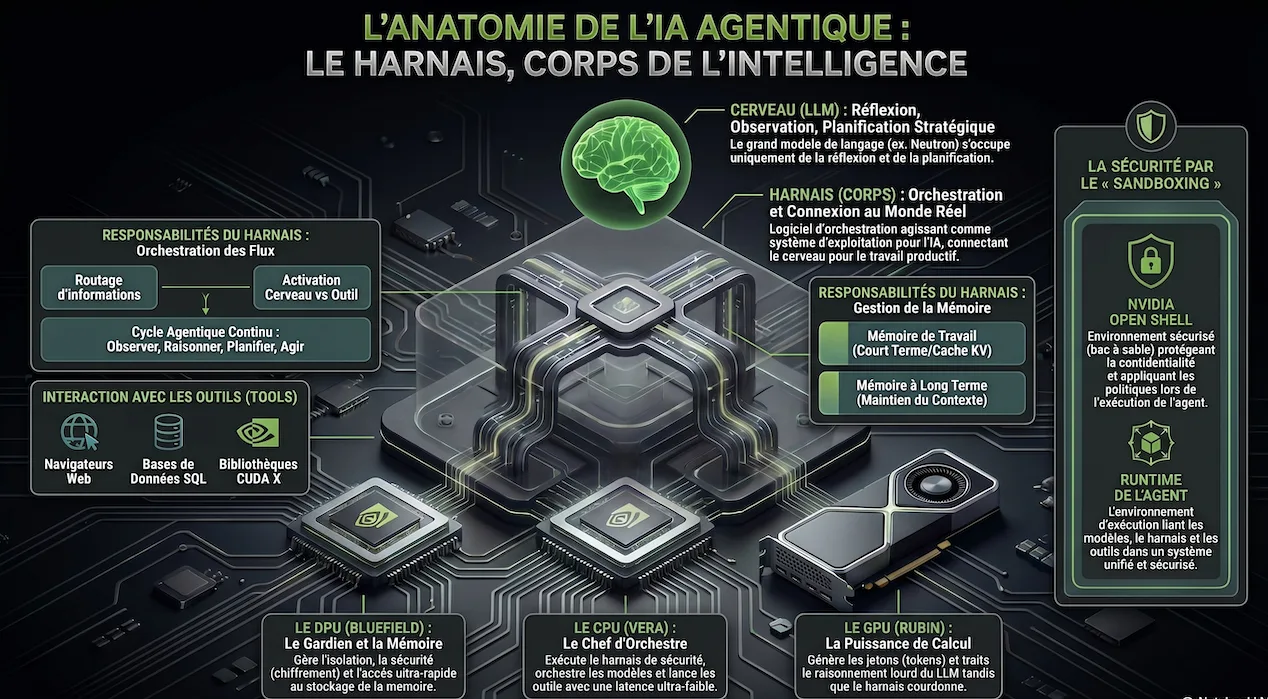
Orchestration, mémoire, outils, sécurité : le « harnais » est la couche qui rend l'IA agentique utile, gouvernable et déployable.
Définition, impacts et opportunités de l'IA agentique : nouveaux usages, nouvelle architecture cloud, nouveaux PC et enjeux de gouvernance.
Retour d'expérience sur l'usage des agents IA en dev : où se crée la valeur, où ça brûle du budget, et comment cadrer l'usage.
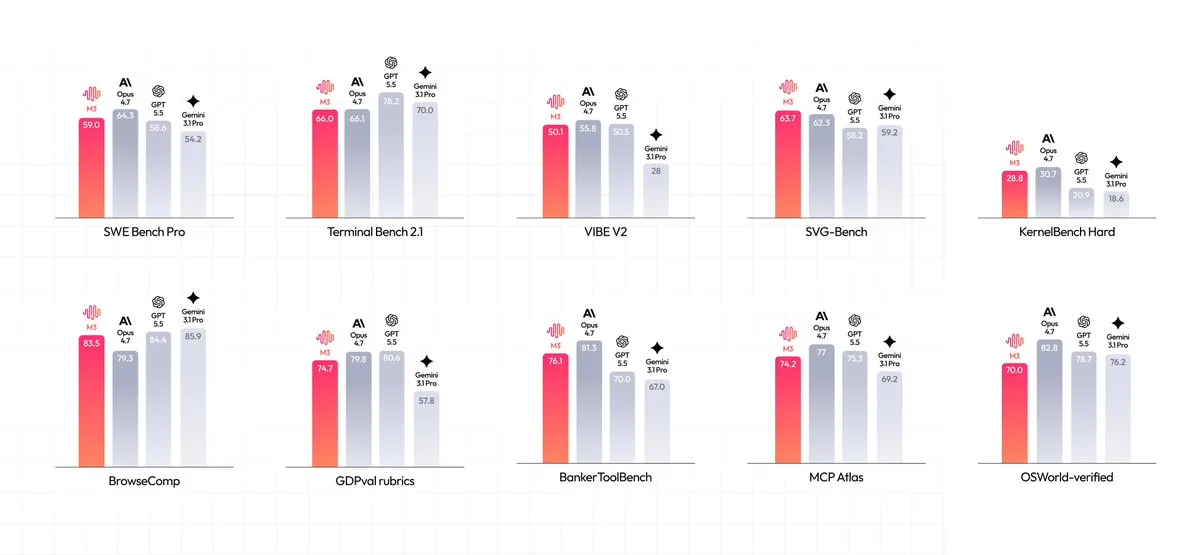
MiniMax M3 annonce trois atouts clés : performances de code/agents, contexte 1M via attention sparse, et multimodal natif.
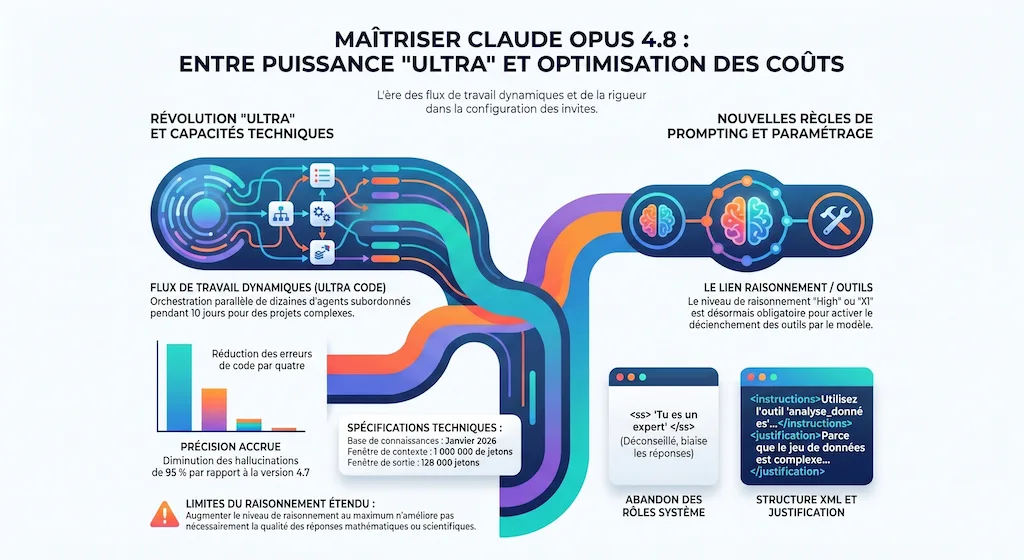
Analyse de Claude Opus 4.8 : nouveautés agentiques, limites de contexte, risques de coûts et méthode concrète pour l'exploiter sans dérapage.
L'IA produit des gains réels souvent invisibles dans les KPI et la comptabilité. Voici comment capturer cette valeur et piloter vos décisions.
Comprendre l'IA agentique, ses vrais usages en entreprise et les étapes concrètes pour automatiser sans perdre le contrôle.
Comment les Goals de Codex transforment vos prompts en boucle autonome basée sur des preuves, idéale pour bugs, perf et tests instables.
Comprendre le Codex Evaluation Harness : tester du code généré par IA, mesurer pass@k et intégrer un harnais sécurisé dans votre CI/CD.
Microsoft classe 40 métiers très exposés à l'IA. Ce que cela veut dire (et ne veut pas dire) et comment adapter vos rôles et processus.
Réduisez coûts et latence des LLM avec deux formats d'output (Caveman et RTK) + modèles de prompts et règles de choix.
Comprendre Copy Fail (CVE-2026-31431) et les mesures concrètes pour réduire le risque sur vos serveurs Linux, cloud et conteneurs.
Un cas réel, 4 leviers concrets et une méthode de discipline pour diviser la consommation de tokens de Claude Code sans perdre en qualité.
Une étude de cas sur les risques des agents IA en production et les garde-fous à mettre en place.
Claude for Small Business automatise vos processus comptables, marketing et opérationnels en se connectant à vos outils existants.
EC2 intimide beaucoup d'agences web. Voici une analyse directe de ce que c'est, quand l'utiliser, et quand l'éviter — sans jargon inutile.
Au-delà du battage médiatique, voici les changements concrets que l'IA apporte aux agences web en 2026 — et comment en tirer parti avant vos concurrents.
Ce blog, pourquoi il existe, et ce que vous pouvez attendre de chaque article. Un premier billet pour planter le décor.
Une veille tech utile, claire et accessible
Analyses sur l'IA, les technologies, le cloud, le marketing et l'entrepreneuriat — directement dans votre boîte mail.
Je m'abonne