La course aux modèles d’IA générative s’est longtemps jouée sur la taille des paramètres et la qualité des réponses. Z.ai déplace le terrain de jeu avec GLM-5.2, un modèle open-source qui mise sur sa capacité à tenir un projet entier en mémoire pendant des heures de travail continu, sans perdre le fil.
C’est un positionnement précis : pas un modèle généraliste de plus, mais un outil pensé pour les tâches longues et complexes, le genre de travail qu’on confierait habituellement à un développeur senior pendant plusieurs jours.
Ce qui s’est passé
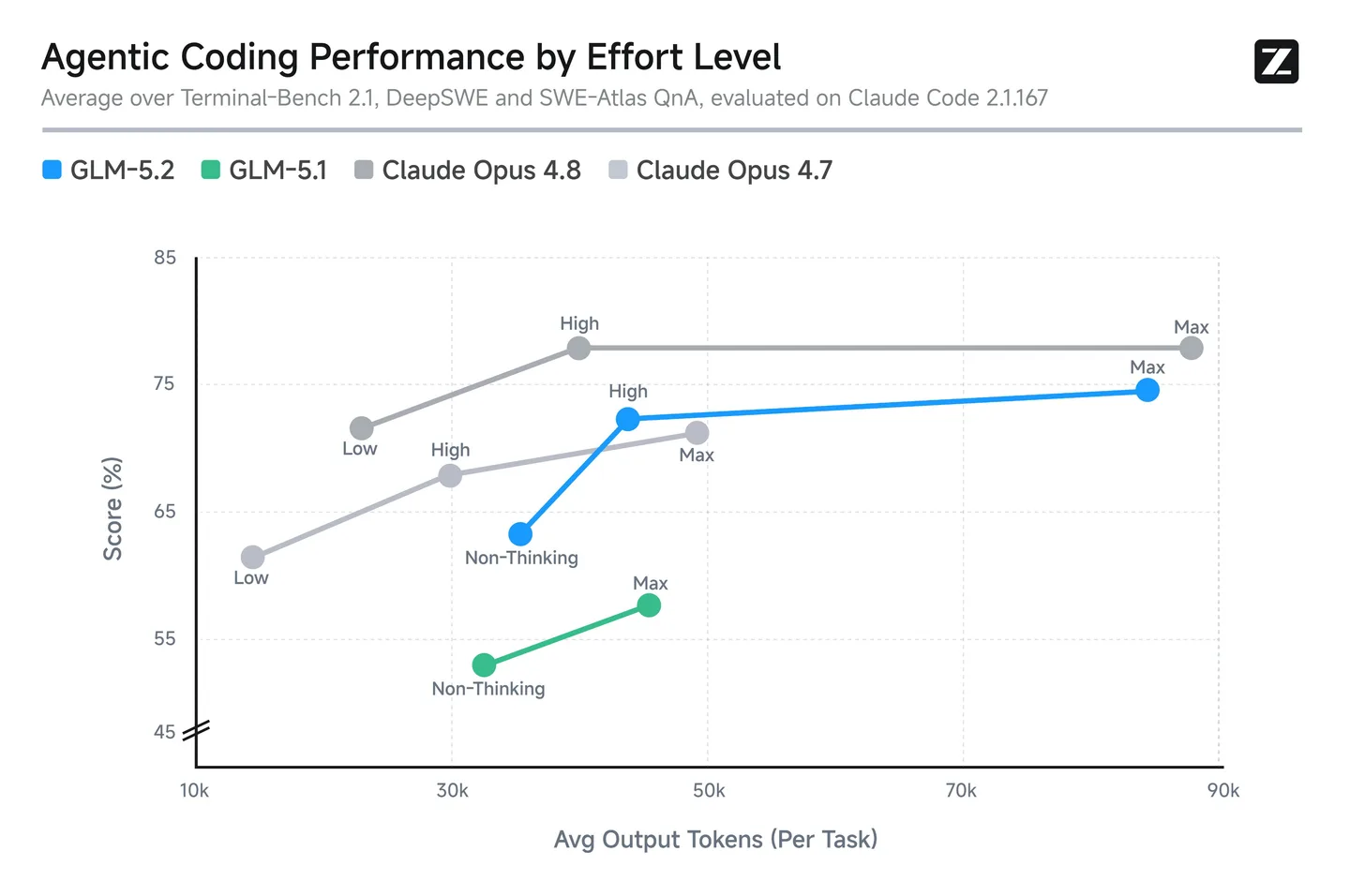
Z.ai a publié GLM-5.2, la nouvelle version de sa famille de modèles GLM. L’argument central du lancement tient en une phrase : un contexte de 1 million de tokens, mais surtout un contexte « réellement utilisable » à cette taille, selon Z.ai.
La nuance compte. Plusieurs fournisseurs annoncent depuis un moment des fenêtres de contexte gigantesques, mais la qualité des réponses se dégrade souvent à mesure que le contexte se remplit. Z.ai affirme avoir entraîné GLM-5.2 spécifiquement pour des scénarios d’agents de programmation sur des tâches longues, et que le modèle conserverait les décisions d’architecture prises en début de tâche plutôt que de les perdre en cours de route.
Concrètement, l’entreprise présente GLM-5.2 comme capable de prendre en charge un projet logiciel complet, des besoins jusqu’au produit déployable, en une seule tâche continue. Le modèle peut analyser un projet existant et en produire l’architecture, mener une refactorisation de bout en bout en respectant des contraintes fixées à l’avance, ou encore migrer une application web vers une mini-application WeChat en respectant les limites de la plateforme cible.
Sur les bancs d’essai techniques cités par Z.ai, GLM-5.2 se présenterait comme le modèle open-source le plus performant en programmation, avec un écart réduit face aux modèles propriétaires de référence sur certains tests comme Terminal-Bench 2.1.
Pourquoi c’est important
Le contexte limité a toujours été le talon d’Achille des outils d’IA pour le développement. Un modèle qui « oublie » la structure d’un projet après quelques échanges force le développeur à tout réexpliquer, ou pire, produit du code qui contredit des décisions prises plus tôt dans la même session.
Si GLM-5.2 tient vraiment sa promesse sur la stabilité à grande échelle, ça change la nature des tâches qu’on peut déléguer à un agent IA. On passe de la génération de fonctions isolées à des chantiers entiers : une refonte de module, une migration de base de données, une adaptation mobile complète.
C’est aussi un signal pour le marché des outils IA en général. L’arrivée d’un modèle open-source qui s’approche sérieusement des modèles propriétaires les plus chers met une pression à la baisse sur les prix et oblige les fournisseurs établis à justifier leur écart de performance.
Ce que cela change pour les entreprises
Pour une agence ou une équipe technique qui gère plusieurs projets clients en parallèle, un modèle capable de tenir un projet entier en mémoire réduit le temps passé à réexpliquer le contexte à chaque session de travail. C’est un gain réel, mais il faut le mesurer à l’usage plutôt que sur la foi des chiffres annoncés par le fournisseur du modèle.
Le fait que GLM-5.2 soit open-source ouvre aussi une option stratégique : une organisation qui héberge ses propres modèles, ou qui travaille avec un fournisseur d’infrastructure flexible, peut potentiellement réduire sa dépendance exclusive à un fournisseur propriétaire. Cette option n’a de valeur que si l’équipe a la capacité technique de l’exploiter correctement.
Pour les organisations qui n’ont pas d’équipe technique interne, l’enjeu reste le même qu’avec tout nouvel outil IA : la qualité du résultat final dépend autant de la façon dont le modèle est encadré et vérifié que de ses capacités brutes.
Les opportunités
Les cas d’usage les plus prometteurs touchent les tâches qui demandent une compréhension globale d’un système existant : audits techniques, refactorisations, migrations entre frameworks ou plateformes. Ce sont des tâches où l’oubli de contexte coûte cher en erreurs et en retouches.
La capacité du modèle à produire un plan d’exécution avant d’agir, puis à vérifier son propre travail par des tests, correspond aussi à une demande réelle des équipes techniques : pouvoir encadrer un agent IA avec des règles strictes plutôt que de lui laisser une liberté totale.
L’aspect open-source mérite l’attention des organisations qui développent leurs propres outils ou intègrent l’IA dans leurs produits. Un modèle performant et accessible sans dépendance à un fournisseur unique change les options de négociation et de continuité.
Les risques ou limites
Les chiffres de performance cités proviennent de Z.ai elle-même. Les comparaisons avec d’autres modèles, même appuyées sur des bancs d’essai reconnus dans l’industrie, méritent d’être vérifiées par des tests indépendants avant de devenir un critère de décision.
Un contexte de 1 million de tokens ne règle pas la question fondamentale de la fiabilité. Un agent qui maintient sa cohérence sur une tâche longue peut tout de même propager une erreur initiale de façon tout aussi cohérente sur l’ensemble de la tâche. La supervision humaine reste nécessaire, particulièrement sur les décisions d’architecture et les contraintes métier qui ne sont pas explicitement documentées.
L’écosystème autour d’un modèle plus récent et moins établi que les modèles dominants reste un facteur à considérer : disponibilité de l’API, documentation, support, et stabilité à long terme du fournisseur.
Mon analyse
Ce qui distingue GLM-5.2 de la plupart des annonces de modèles, c’est le choix de l’angle. Plutôt que de répéter l’argument générique de la qualité de réponse, Z.ai construit son positionnement autour d’un problème précis : la dégradation de la cohérence sur les tâches longues. C’est un problème que toute personne qui a utilisé un agent IA sur un vrai projet a déjà rencontré.
Reste que les chiffres de performance, aussi précis soient-ils, viennent de l’entreprise qui vend le modèle. L’écart cité face à Opus sur certains bancs d’essai est plausible, mais la seule façon de savoir si GLM-5.2 tient ses promesses sur un projet réel, c’est de le tester sur un projet réel.
Pour une agence comme la mienne, l’intérêt n’est pas de remplacer les outils déjà en place, mais d’élargir l’éventail d’options pour des tâches spécifiques. Un modèle à contexte massif s’envisage comme une pièce de plus dans une stratégie d’outils, pas nécessairement comme remplacement unique.
Conclusion
GLM-5.2 confirme une tendance de fond : la prochaine bataille des modèles d’IA ne se joue plus seulement sur la qualité brute des réponses, mais sur la capacité à tenir des tâches longues sans perdre le fil. C’est une évolution utile pour qui travaille sur des projets complexes.
La prudence reste de mise sur les chiffres annoncés et la vérification reste la seule façon fiable d’évaluer un outil pour un usage réel. Avant d’adopter un nouveau modèle pour des tâches critiques, testez-le sur un projet à faible enjeu et mesurez les résultats vous-même.
Vous souhaitez évaluer les meilleurs outils IA pour vos projets de développement ou d’automatisation ? FD Stratégies peut vous aider à structurer cette réflexion et à choisir les solutions adaptées à votre contexte.